Retrieving and Analyzing Finnish Cultural Metadata with R
Finna & Finto, Fennica & Viola
Akewak Jeba, Julia Matveeva, Leo Lahti
2026-01-22
Workshop overview
- What is Finna (incl. Fennica & Viola)
- Why use R for cultural metadata
- The
finnaR package - Case study 1: Fennica
- Case study 2: Viola
- Enrichment with Finto / KANTO
- Multinomial regression on enriched Fennica
- Practical exercises (+ solutions)
- Questions
What is Finna?
- Finnish national search service for museums, libraries, and archives
- Maintained by the National Library of Finland + partner institutions
- Provides open interfaces for search and reuse
Key idea: Finna is an aggregation layer, not a single database.
Fennica and Viola inside Finna
- Fennica: Finnish National Bibliography (books/publications; long historical coverage)
- Viola: national discography and sheet music bibliography (recordings, scores, music archives)
Why use R?
Reproducible workflows: retrieval → cleaning → analysis → visualization
Scales beyond manual browsing
Bridges cultural metadata to:
- statistics
- ML
- text analysis
- enrichment via authority data
The finna R package
- Core entry point:
search_finna() - Bulk retrieval patterns (limits, batching)
- Tidy outputs (tibbles) → easy
dplyr+ggplot2
Setup (install)
Setup (load)
🔹 Basic search (Introduction to finna)
🔹 Subject search example
🔹 Search operators (+ and !-)
🔹 Fuzzy and proximity search
Case study 1: Fennica
Basic Fennica search
🔹 19th-century Fennica (1809–1917)
🔹 Fennica publication year distribution
#| label: fennica-plot
#| eval: false
library(finna)
library(ggplot2)
fennica <- search_finna(
"*",
filters = c('collection:"FEN"', 'search_daterange_mv:"[1809 TO 1918]"'))
refined_data <- refine_metadata(fennica)
top_plot(refined_data$Year, field = "Year", ntop = 10, show.percentage = TRUE) +
xlab("Publication Year") +
ylab("percentage distribution of Publications") 🎼 Case study 2: Viola (official vignette)
🔹 Batch retrieval across centuries
viola_results <- fetch_viola_records(
base_query = "*",
base_filters = c('collection:"VIO"'),
year_ranges = list(
c(0, 1699),
c(1700, 1799),
c(1800, 1899)
),
include_na = TRUE,
limit_per_query = 100000,
total_limit = 500,
delay_after_query = 3
)
nrow(viola_results)
viola_results %>% slice_head(n = 6)🔹 Viola: top-10 authors
🗂️ Finna collection overview (archives example)
🗂️ Harvest Metadata from an OAI-PMH Server
Enrichment: Fennica authors → KANTO
library(finto)
library(stringr)
library(dplyr)
data("fennica_subset", package = "finna")
authors_df <- finto::get_kanto(fennica_subset)
fennica_subset2 <- fennica_subset %>%
mutate(authorID = str_extract(author_ID, "\d{9}"))
authors_df_clean <- authors_df %>%
distinct(author_ID, .keep_all = TRUE) %>%
rename(authorID = author_ID)
merged_data <- left_join(
fennica_subset2,
authors_df_clean,
by = "authorID"
)
merged_data %>% slice_head(n = 5)Modeling genre probabilities with categorical predictors
Setup (install)
Load the data
url <- "https://a3s.fi/swift/v1/AUTH_3c0ccb602fa24298a6fe3ae224ca022f/fennica-container/harmonized/workshop_dariah.tsv"
df_model <- read.table(
file = url,
sep = "\t",
header = TRUE,
colClasses = "character",
fileEncoding = "UTF-8",
quote = "\"",
comment.char = "",
stringsAsFactors = FALSE
)
# Choose a common reference level (baseline) for interpretation
df_model$genre <- fct_relevel(df_model$genre, "Romaanit")Quick sanity checks
Tietokirjallisuus Romaanit Runot
14652 5336 3002
Novellit, kertomukset Draama Yhdistelmä
1908 1715 276
Kaunokirjallisuus Puheet, esitelmät
263 229
female male Unknown
2143 21287 3951
Unknown Other kirjailija respondentti kääntäjä toimittaja
11030 5318 2413 2281 2261 880
professori opettaja kirjoittaja rehtori
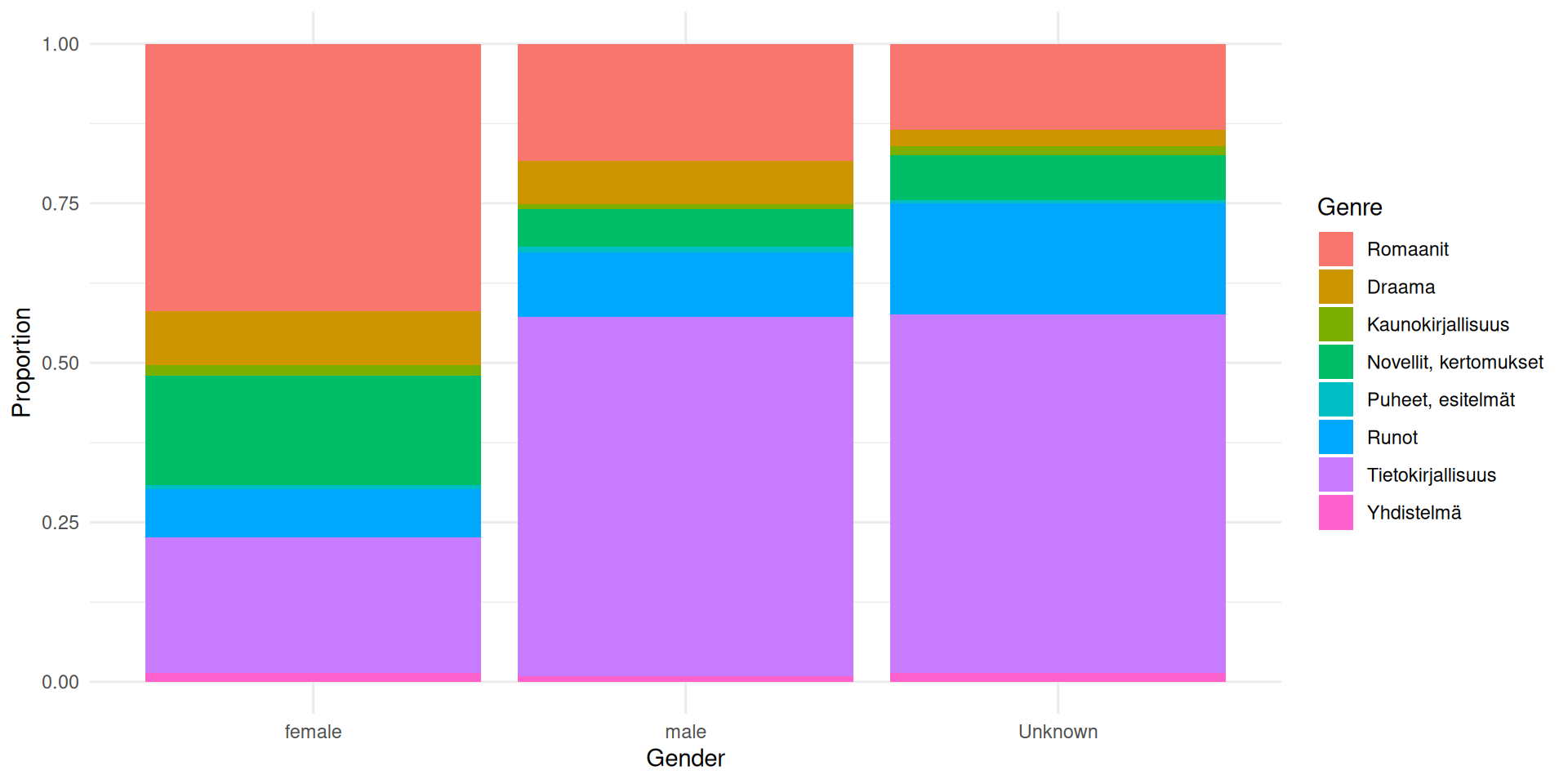
814 787 714 460 Plot 1: Genre composition by gender (proportions)
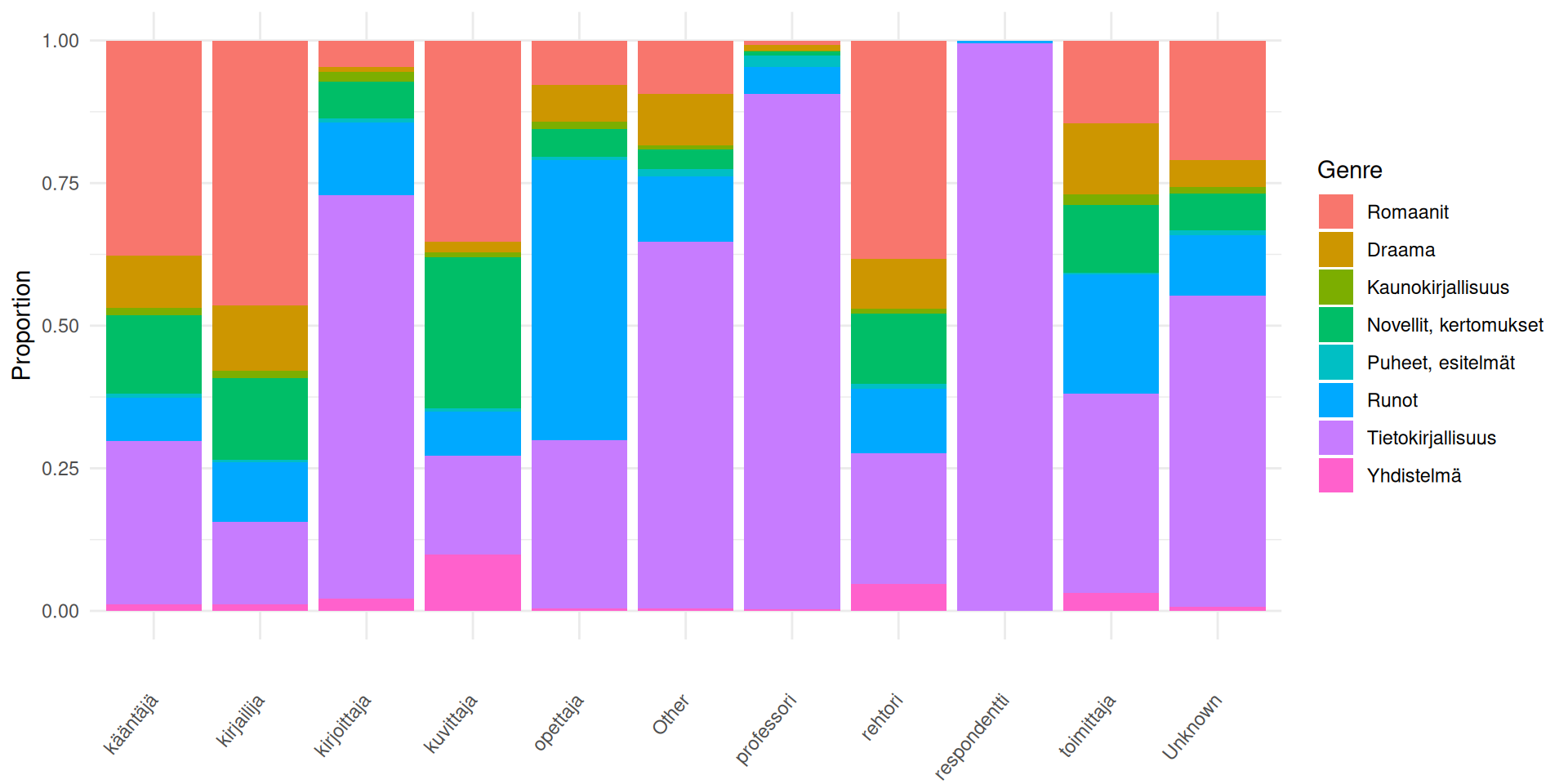
Plot 2: Genre composition by profession (proportions)
Multinomial regression
Call:
multinom(formula = genre ~ gender + profession_primary, data = df_model,
trace = FALSE)
Coefficients:
(Intercept) gendermale genderUnknown
Draama -1.8243281 0.48425545 0.1714273
Kaunokirjallisuus -3.3856521 0.02641162 1.0587280
Novellit, kertomukset -0.8062308 -0.26404611 0.5445759
Puheet, esitelmät -4.6867499 0.75068731 0.1995744
Runot -2.4859831 0.99940256 2.3762132
Tietokirjallisuus -1.4358849 1.30221822 1.8288469
Yhdistelmä -3.6842853 0.17945458 1.7669436
profession_primarykirjailija
Draama 0.04681887
Kaunokirjallisuus -0.16985840
Novellit, kertomukset -0.19087778
Puheet, esitelmät -0.72349059
Runot 0.17508161
Tietokirjallisuus -0.82330625
Yhdistelmä -0.12057560
profession_primarykirjoittaja profession_primarykuvittaja
Draama -0.3716476 -1.51862826
Kaunokirjallisuus 2.3993149 -0.24109521
Novellit, kertomukset 1.3345576 0.71805513
Puheet, esitelmät 2.0457859 -0.24699555
Runot 2.5447221 0.07848643
Tietokirjallisuus 2.9248295 -0.43434645
Yhdistelmä 2.6939746 2.23956433
profession_primaryopettaja profession_primaryOther
Draama 1.2608868 1.34599257
Kaunokirjallisuus 1.5794176 0.68723728
Novellit, kertomukset 0.5652738 0.01392671
Puheet, esitelmät 1.3594645 2.04404504
Runot 3.4845860 1.74389986
Tietokirjallisuus 1.6570524 2.13285118
Yhdistelmä 0.6248211 0.37178627
profession_primaryprofessori profession_primaryrehtori
Draama 1.743904 -0.13817991
Kaunokirjallisuus 1.638005 -0.41709494
Novellit, kertomukset 1.033936 -0.05902285
Puheet, esitelmät 4.923200 0.14617129
Runot 3.339814 0.27443012
Tietokirjallisuus 4.947652 -0.37683755
Yhdistelmä 2.414373 1.43085769
profession_primaryrespondentti
Draama 0.6175326
Kaunokirjallisuus -0.6254910
Novellit, kertomukset -1.1796540
Puheet, esitelmät 0.5462942
Runot 6.2565483
Tietokirjallisuus 10.1538133
Yhdistelmä 0.4946164
profession_primarytoimittaja profession_primaryUnknown
Draama 1.2537584 -0.01493913
Kaunokirjallisuus 1.2711562 0.04804269
Novellit, kertomukset 0.8058559 -0.38969916
Puheet, esitelmät 0.2702575 0.97441631
Runot 1.9311286 0.34802361
Tietokirjallisuus 1.1261798 1.03670876
Yhdistelmä 1.9779348 -0.39957036
Std. Errors:
(Intercept) gendermale genderUnknown
Draama 0.10912012 0.08883404 0.14270491
Kaunokirjallisuus 0.24177562 0.18946770 0.24328932
Novellit, kertomukset 0.08650150 0.07138198 0.10593058
Puheet, esitelmät 0.35367304 0.26546358 0.36743602
Runot 0.11993771 0.09479875 0.11444010
Tietokirjallisuus 0.07896528 0.06488203 0.08069092
Yhdistelmä 0.26302595 0.20292697 0.26873432
profession_primarykirjailija
Draama 0.10288901
Kaunokirjallisuus 0.25748123
Novellit, kertomukset 0.09076228
Puheet, esitelmät 0.42285126
Runot 0.10917163
Tietokirjallisuus 0.08142748
Yhdistelmä 0.27620628
profession_primarykirjoittaja profession_primarykuvittaja
Draama 0.4551472 0.3735389
Kaunokirjallisuus 0.3756909 0.5335691
Novellit, kertomukset 0.2359878 0.1416478
Puheet, esitelmät 0.5540525 0.7531100
Runot 0.2183049 0.2109636
Tietokirjallisuus 0.1856609 0.1533788
Yhdistelmä 0.3700779 0.2665901
profession_primaryopettaja profession_primaryOther
Draama 0.2057370 0.10069325
Kaunokirjallisuus 0.3867514 0.25625036
Novellit, kertomukset 0.2159991 0.10944311
Puheet, esitelmät 0.5764924 0.29056345
Runot 0.1625823 0.10327487
Tietokirjallisuus 0.1549123 0.07144812
Yhdistelmä 0.5996751 0.29736302
profession_primaryprofessori profession_primaryrehtori
Draama 0.5278332 0.1919932
Kaunokirjallisuus 1.0516618 0.5384245
Novellit, kertomukset 0.5769589 0.1669830
Puheet, esitelmät 0.5411295 0.5718669
Runot 0.4421894 0.1787756
Tietokirjallisuus 0.4080617 0.1343134
Yhdistelmä 0.8304904 0.3041265
profession_primaryrespondentti
Draama 5.505767
Kaunokirjallisuus 23.293044
Novellit, kertomukset 10.192345
Puheet, esitelmät 17.428738
Runot 3.161731
Tietokirjallisuus 3.147812
Yhdistelmä 14.523978
profession_primarytoimittaja profession_primaryUnknown
Draama 0.1515957 0.09413559
Kaunokirjallisuus 0.3239207 0.22286312
Novellit, kertomukset 0.1478171 0.08435518
Puheet, esitelmät 0.6410573 0.28371971
Runot 0.1428368 0.09666364
Tietokirjallisuus 0.1184175 0.06004265
Yhdistelmä 0.2900095 0.25538190
Residual Deviance: 66109.7
AIC: 66291.7 Predicted probabilities for each row (N x K)
Romaanit Draama Kaunokirjallisuus Novellit, kertomukset
1 0.2280022 0.05881185 0.008315801 0.05295165
2 0.2280022 0.05881185 0.008315801 0.05295165
3 0.0885456 0.08907133 0.006119708 0.03078931
4 0.2280022 0.05881185 0.008315801 0.05295165
5 0.2280022 0.05881185 0.008315801 0.05295165
6 0.2280022 0.05881185 0.008315801 0.05295165
7 0.2280022 0.05881185 0.008315801 0.05295165
8 0.2280022 0.05881185 0.008315801 0.05295165
9 0.4392490 0.12051962 0.012883758 0.12445096
10 0.4392490 0.12051962 0.012883758 0.12445096
Puheet, esitelmät Runot Tietokirjallisuus Yhdistelmä
1 0.011795392 0.07302474 0.5625035 0.004594933
2 0.011795392 0.07302474 0.5625035 0.004594933
3 0.013349783 0.11453002 0.6537350 0.003859251
4 0.011795392 0.07302474 0.5625035 0.004594933
5 0.011795392 0.07302474 0.5625035 0.004594933
6 0.011795392 0.07302474 0.5625035 0.004594933
7 0.011795392 0.07302474 0.5625035 0.004594933
8 0.011795392 0.07302474 0.5625035 0.004594933
9 0.004159992 0.11834067 0.1686952 0.011700833
10 0.004159992 0.11834067 0.1686952 0.011700833[1] 27381Average predicted probabilities by gender
avg_probs_by_gender <- as.data.frame(p_hat) %>%
mutate(gender = df_model$gender) %>%
group_by(gender) %>%
summarise(across(everything(), mean, na.rm = TRUE), .groups = "drop") %>%
pivot_longer(-gender, names_to = "genre", values_to = "p")
ggplot(avg_probs_by_gender, aes(x = gender, y = p, fill = genre)) +
geom_col(position = "fill") +
labs(x = "Gender", y = "Average predicted probability", fill = "Genre") +
theme_minimal()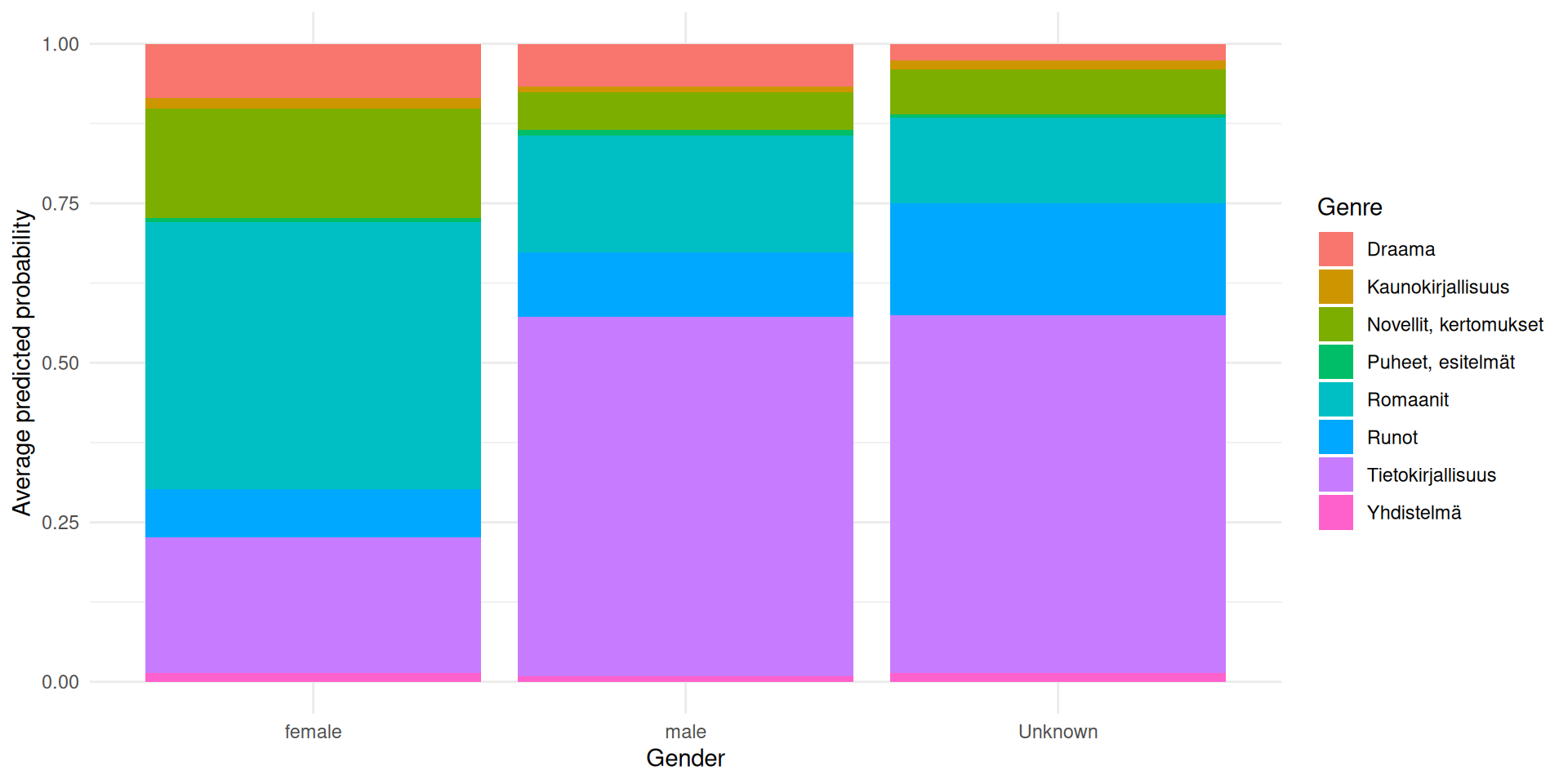
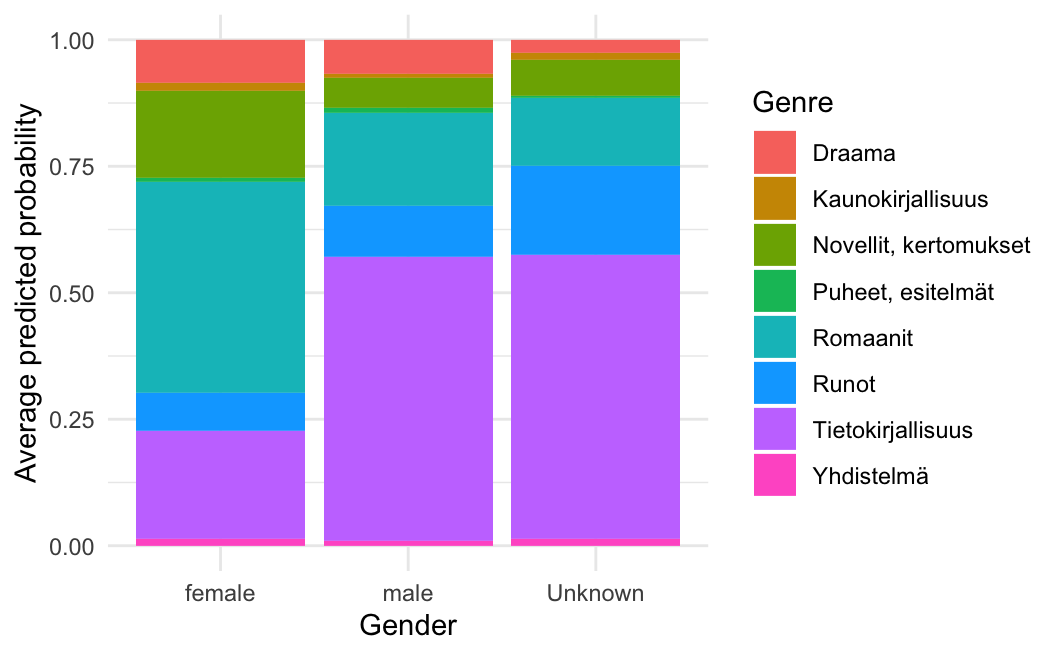
Exercises (with solutions)
Exercise 1 (Fennica): time window trend
Task
- Retrieve Fennica records for 1900–1950 (sample is fine)
- Plot publications per year
Exercise 1 — Solution
fen_1900_1950 <- search_finna(
query = "*",
filters = c(
'collection:"FEN"',
'search_daterange_mv:"overlap|[1900 TO 1950]"'
),
limit = 500
)
fen_1900_1950 %>%
mutate(Year = suppressWarnings(as.integer(Year))) %>%
filter(!is.na(Year)) %>%
count(Year) %>%
ggplot(aes(Year, n)) +
geom_line() +
labs(
title = "Fennica publications per year (1900–1950 sample)",
x = "Year",
y = "Count"
)Exercise 2 (Fennica): compare two languages or formats
Task
- From your Fennica sample, pick two values of
Language(orFormats) - Compare counts over time (facet or color)
Exercise 2 — Solution
fen <- fen_1900_1950 %>%
mutate(
Year = suppressWarnings(as.integer(Year)),
Language = as.character(Language)
) %>%
filter(!is.na(Year), !is.na(Language))
top_lang <- fen %>%
count(Language, sort = TRUE) %>%
slice_head(n = 2) %>%
pull(Language)
fen %>%
filter(Language %in% top_lang) %>%
count(Year, Language) %>%
ggplot(aes(Year, n, color = Language)) +
geom_line() +
labs(
title = "Two most common languages over time (sample)",
x = "Year",
y = "Count"
)Exercise 3 (Viola): top-10 authors and share
Task
- Use
fetch_viola_records()for a small time window (e.g., 1900–1949) - Plot top-10 authors with percentages
Exercise 3 — Solution
viola_1900_1949 <- fetch_viola_records(
base_query = "*",
base_filters = c('collection:"VIO"'),
year_ranges = list(c(1900, 1949)),
include_na = FALSE,
limit_per_query = 100000,
total_limit = 500,
delay_after_query = 1
)
ref_v <- refine_metadata(viola_1900_1949)
top_plot(ref_v$Author, field = "Author", ntop = 10, show.percentage = TRUE) +
xlab("Author") +
ylab("Percentage")Exercise 4 (Enrichment): join KANTO and inspect new fields
Task
- Load
fennica_subset(built-in demo dataset) - Fetch KANTO author data with
get_kanto() - Join back and list 5 enriched columns you didn’t have before
Exercise 4 — Solution
data("fennica_subset", package = "finna")
authors_df <- finto::get_kanto(fennica_subset)
fennica_subset2 <- fennica_subset %>%
mutate(authorID = stringr::str_extract(author_ID, "\\d{9}"))
authors_df_clean <- authors_df %>%
distinct(author_ID, .keep_all = TRUE) %>%
rename(authorID = author_ID)
joined <- left_join(fennica_subset2, authors_df_clean, by = "authorID")
added_cols <- setdiff(names(joined), names(fennica_subset2))
added_cols %>% head(20)
# Example: show a few enriched fields if present
joined %>% select(any_of(c("author_name", "authorID", "uri", "type")), any_of(added_cols)) %>%
slice_head(n = 3)Take-home message
- Finna metadata is research-ready in R
finnaenables scalable, reproducible cultural analytics- Enrichment + stats unlock new research questions
Questions?
Troubleshooting
- API limits: Use
limitparameter and batching - Rate limiting: Add
delay_per_queryparameter - Missing data: Use
filter(!is.na(field)) - Date parsing: Use
suppressWarnings(as.integer(Year))
Cheat sheet
# Basic search
search_finna(query, filters, limit)
# Fennica specific
search_finna("*", filters = c('collection:"FEN"'))
# Viola specific
search_finna("*", filters = c('collection:"VIO"'))
# Viola batching
fetch_viola_records(base_query, year_ranges)
# Metadata harvest
harvest_oai_pmh(
base_url,
metadata_prefix,
user_agent = "FinnaHarvester/1.0",
record_limit = NULL
)
# Enrichment
finto::get_kanto(data)